
In recent years, the world of Artificial Intelligence has seen lightning-fast developments. Major players like OpenAI, Google, and Meta have released increasingly powerful models, rolling out frequent and substantial updates. This evolution has been disruptive, transforming AI from a technological curiosity into a critical resource for businesses, professionals, and consumers.
However, since mid-2024, the race for pure technical performance has begun to slow. Where each new language model previously introduced notable breakthroughs, the improvements between one version and the next are more incremental today. The “wow factor” is diminishing, shifting the focus from record-breaking results to successfully integrating AI into workflows, industrial processes, and everyday experiences.
As a result, the AI sector is entering a consolidation phase this year. We won’t necessarily see linguistically revolutionary models every month, but we will see growth in areas like multi-channel deployment, more integrated use cases, and more mature interfaces. The goal is for companies to embed Generative AI seamlessly into the digital fabric across business operations, personal productivity, and even physical systems.
In this article, adapted from our recent webinar, we explore the emerging trends in Generative AI during this period of stabilization and maturation.
AI Trend 2025: multichannel, the first great frontier
Multichannel capability is a cornerstone of this new era. Until recently, interacting with AI models was almost exclusively text-based. Today, the landscape is rapidly expanding. The very concept of a “channel” now extends beyond text to include voice, images, video, direct on-screen actions, and much more. We are witnessing a transformation that aims to integrate AI everywhere, making it an operational tool rather than confining it to a single environment or input/output format.
Real-time APIs, the basis for instant interaction
Real-time APIs ensure fluid, low-latency interactions, processing input and delivering output in milliseconds. This evolution is crucial for voice channels, where, in the past, the process involved separate steps: speech-to-text, text processing, and then text-to-speech. Thanks to Real-Time APIs and advanced models, we’re moving toward a direct voice-to-voice approach, eliminating the gaps between input and output.
This innovation goes beyond traditional IVR systems based on standard flows and numeric keypads, enabling more natural, immediate, and personalized conversations. Still, challenges remain, such as real-time output control and the limited availability of voice-to-voice models for less common languages or local dialects. While vertical applications and use cases are still in the testing phase, the trend is clear: by 2025, voice will become a primary, integrated user experience channel.
Gemini 2.0, toward Large Action Models (LAM)
Another key element of multichannel development is AI’s ability to interact with the user’s entire digital ecosystem through text or voice inputs. This progress introduces the LAM (Large Action Model) concept, in which AI doesn’t just interpret content—it takes action directly on conversational interfaces, applications, and systems.
Gemini 2.0 is a step in this direction. It’s a multimodal suite that can process real-time input from text, images, video, and even screen sharing. AI becomes an active collaborator in operational tasks like filling out spreadsheets, navigating files, or using web applications.
Anthropic Computer Use, AI at the helm of your computer
If Gemini 2.0 lays the groundwork, Anthropic Computer Use takes it a step further. It’s not just about sharing your screen with the AI; you’re giving it “control” of the interface. Users can ask the AI to execute complex tasks, like organizing data from one window to another or completing documents. In this scenario, AI becomes an operational co-pilot, showing the user each action it takes and bridging the gap between knowledge and execution. This technology paves the way for business digitalization and advanced industrial use cases where AI models can automate repetitive tasks and boost workflow efficiency and productivity.
Project Mariner, native integration into the user experience
Google’s Project Mariner provides a solution similar to Anthropic’s but integrated directly into the Chrome browser. The goal is to make AI a native element of the browsing experience. No more external tools—just functions built into one of the world’s most widely used digital channels. The AI can analyze, reorganize, and produce content, and interact with web pages and cloud applications, all within a single native environment.
Runner H, efficiency as a key parameter
Runner H draws attention to another critical aspect: tool efficiency. It’s not enough for AI to perform actions; it needs to complete them in as few steps as possible. In a context where AI becomes an operational actor, the ability to optimize workflows, reduce clicks, and streamline required operations makes all the difference. This focus on productivity and operational efficiency reflects a maturing market where competition hinges not only on “doing it better” but also on “doing it faster and leaner.”
NotebookLM, moving toward complex content creation
Finally, multichannel capabilities extend to the AI’s creative and interpretive powers. Google’s NotebookLM allows you to input a document, article, or text and have the model work on it creatively. This evolution isn’t just about extracting information or summarizing content; it’s about producing complex outputs. For example, you could create a podcast episode where the AI generates a believable conversation between two interlocutors discussing the original document’s content. This creative effort dramatically broadens the horizons for AI applications, enabling new forms of engagement and storytelling.
Multimodality, integrating different data types
While multichannel focuses on “where” and “how” AI interacts with the user, multimodality AI trend concerns the types of data AI can process and generate text, images, audio, video, and even interface actions. The challenge is to enable models to interpret and produce content from diverse sources coherently and effectively.
Traditionally, AI models focused on text. A prime example is ChatGPT, which takes text input and returns text output. However, recent years have pushed the boundaries, introducing models that can generate images, synthesize realistic voices, create music, and even control robots. The shared goal is to unify multiple formats into a single experience, allowing fluid transitions between text, images, audio, and video.
The most complex frontier is video, which isn’t just a sequence of images (frames) but a narrative unfolding over time. To understand and generate video effectively, a model must grasp narrative continuity, logical coherence, and the physical plausibility of scenes.
Sora, OpenAI’s approach to generative video
OpenAI introduced Sora, a model designed to redefine video content creation. Sora can transform text input or static images into short animated clips, offering advanced customization tools like remix (to modify, replace, or reimagine video elements), customizable timelines, and loop and preset options.
Veo 2, Google’s take on coherent video generation
Google responded to the challenge with Veo 2, a multimodal model designed to produce high-quality video with impressive realism. Veo 2 excels at simulating real-world physics and offers advanced camera controls, allowing users to select shooting styles, angles, and complex movements.
Kling, breathing life into static content
From China comes “Kling,” a model that adds motion to static images. Kling can transform simple photographs into short animated videos, adding dynamism and realism to the content. For example, a photo of a car can become a video in which the car moves believably, with wheels turning and reflections changing according to light and viewing angle.
Multisensoriality, from virtual intelligence to physical world interaction
After integrating AI across multiple channels (multichannel) and enabling it to work with various data types (multimodality), the next step is multisensoriality, allowing AI to interact not only with textual, visual, or auditory input but also with the physical world.
Natural language was the first “sense” developed by AI models since language underpins human intelligence. Then came “vision,” as AI learned to process images and video, and “hearing” as it worked with audio. Now, the challenge is implementing touch and movement, enabling models to interact physically. This approach, known as “embodiment,” aims to give AI a body, real or simulated, that can perceive and act on its surroundings.
Two parallel research tracks are emerging:
- Physical Robotics involves developing increasingly agile, precise, and intelligent robots. These robots can fluidly interact with their environment by grasping, moving, assembling, and manipulating objects while performing complex actions.
- World simulation involves creating advanced virtual environments where artificial intelligence (AI) can be trained, tested, and refined at a lower cost and with reduced risk compared to real-world scenarios. For instance, video games offer controlled settings where AI can learn to manage physics, interact with other agents, and handle complex and unexpected situations. After training in these simulated environments, AI models can be transferred to real life more safely and effectively.
Genie 2, creating intelligent agents in simulated environments
Genie 2 is a platform focused on creating virtual agents in complex 3D environments. Imagine a sandbox-style video game scenario where AI must learn to interact with objects, characters, and dynamic settings. For example, an agent could learn to gather resources, craft tools, solve puzzles, and collaborate with other agents, all in a simulated world.
Diamond, tactile intelligence and problem-solving
Diamond is a project focused on teaching AI to perceive and react to simulated tactile stimuli. In a virtual environment, Diamond can learn to distinguish consistency, solidity and shape and manipulate objects accordingly. For instance, the AI can “virtually touch” an object, understand its form, and grasp it correctly.
Worldlabs, integrated training in complex virtual worlds
Worldlabs is a platform that takes simulation to the next level, enabling the creation of full-fledged multisensory digital worlds. Here, AI doesn’t just learn to see or touch but to interact with a complete digital ecosystem—animals, plants, materials with different physical properties, day-night cycles, and changing weather conditions.
NVIDIA’s Omniverse, a platform for industrial simulation
NVIDIA’s Omniverse is an extremely advanced simulation and virtual collaboration platform designed for building digital universes where you can train and test robots, autonomous vehicles, and IoT devices. Its main advantage is that it allows intensive robot training without the risks or costs associated with damaged machinery, production downtime, or accidents.
1X, real robotics serving the industry
Some companies have already begun adopting robots trained in these principles. 1X, for example, integrates autonomous robots into industrial processes, automating repetitive or dangerous tasks for humans.
Economic sustainability, from research to production
As mentioned, AI models are reaching a performance plateau. Once each new generation brought stark improvements, today's advancements are more incremental and less dramatic.
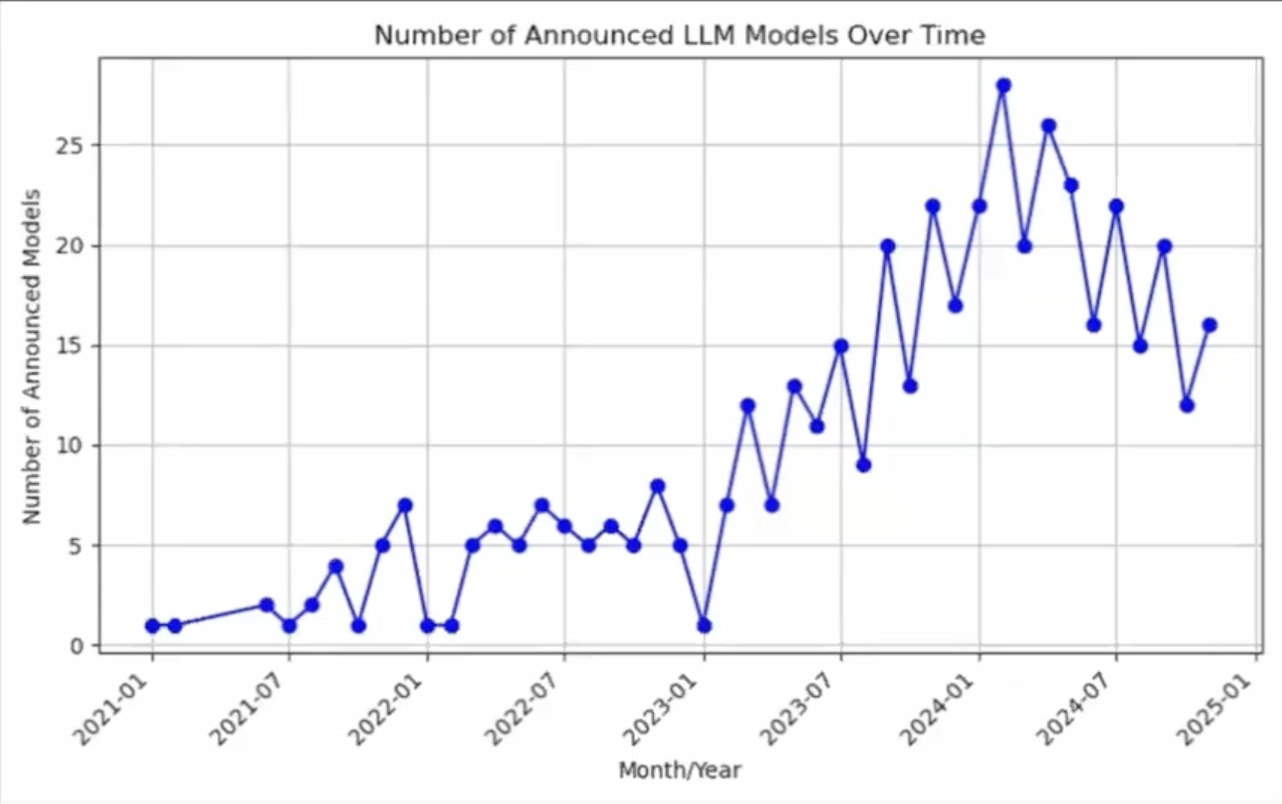
A clear indicator of this shift is the trend in the number of new LLMs announced between 2021 and 2025. After a peak between late 2023 and early 2024, there has been a progressive decline. This decrease reflects a consolidation scenario in which rolling out a new model every month is no longer essential. Instead, the focus is on making existing models economically and operationally sustainable.
This context encourages companies to rethink their strategy, prioritizing the creation of stable, useful, economically sustainable products over pure research.
From experimentation to productization
The focus is moving from “doing it better” to “doing it sustainably and at scale.” It means integrating AI into tangible products and services that people can use daily. The aim is to make AI a standard, natural component in various use cases, from AI agents enhancing customer experience to productivity tools and industrial data analysis platforms.
The keyword here is “productization,” which means turning prototypes and demos into finished products that are configurable, stable, and have a sustainable business model.
Monetization and business models
A prime example is OpenAI. After conquering the market with ChatGPT, the company is experimenting with new monetization models, such as integrated advertising. Similarly, OpenAI and others are looking at historically lucrative sectors like “Military Tech” for partnerships and specialized applications. Though this might seem at odds with the company’s original mission, it reflects the need to compete in a real market, where products and solutions must generate concrete value for investors and adopters.
The market as the final arbiter
Today, the challenge is not just producing advanced technology but creating solutions that can be sold, maintained, integrated into existing processes, and supported over time. Market reality demands tangible revenue streams to cover the high computational costs of large-scale models and continue funding research and development.
The shift from research to production is thus a natural consequence of technological maturity. Companies must find a balance between innovation, ethics, and monetization. The result? A landscape where AI models are less flashy in terms of continuous evolutionary leaps but more solid, accessible, and integrated into everyday applications. In short, economic sustainability becomes necessary for ensuring the continuity of innovation and the widespread adoption of AI in the productive and social fabric.
In conclusion, the evolution of AI over the coming years will be defined by stabilizing performance and making a critical shift from pure research to developing truly integrated and sustainable products. Multichannel deployment, multimodal capability, multisensorial interaction, and economic sustainability will guide innovation, charting a path where AI moves beyond niche technological frontiers to become a fundamental driver of everyday life, productivity, and the global market.
FAQs
1. What areas will AI be applied to in 2025?
In 2025, AI will be deeply rooted in a wide range of sectors, becoming a tangible support for productivity, customer experience, service delivery, creativity, and process optimization. In contact centers, for example, AI agents won’t just provide answers—they’ll anticipate user needs. In industrial settings, AI will guide robots and machinery to reduce waste, while in the digital content realm, it will help create high-quality text, images, and video. This integration will be possible thanks to AI’s natural integration into browsers, cloud applications, and platforms we use every day.
2. Why is the pace of AI technological development slowing down?
It’s less of a slowdown and more of a consolidation phase. After years of rapid advances, new models no longer offer revolutionary leaps with every release. The focus has shifted to reliable, scalable integration of existing solutions, the ability to handle diverse data and formats, and alignment with real workflows. This approach fosters solid, sustainable products that can generate long-term value.
3. How will AI become an integral part of everyday activities?
By 2025, AI will be increasingly woven into the platforms and services we already use without feeling intrusive or hidden. We won’t need to “seek it out”—it will be present in our browsers, data analysis software, automation tools, and home devices. We’ll talk to AI using natural language, assign complex tasks, and tap into its creative and organizational potential. This way, it will become a tangible, reliable partner seamlessly integrated into our digital activities and non-digital daily habits.



